Most documents, I am frequently told, are trivial things of two pages or less and with an expected useful lifetime measured in weeks or less. That may be true in some cases, but I've been a writer of some kind for long enough to care about keeping information available and editable.
The stuff I write tends to live on for years in some form, and tends to require revision at intervals that are just long enough that it's likely I've forgotten the exact details since last time I went over that particular text. If you're only a tiny bit like me, you'll be nodding intensely at those observations.
Note: This piece is also available without trackers but classic formatting only here.
And of course as a technical writer, I've had enough exposure to Microsoft Word that I concur emphatically with essentially all that Charlie Stross wrote in his recent blog post, Why Microsoft Word must Die.
Immediately after reading Charlie's post, I added some thoughts of my own in the comments. Do read the comments or at least skim some, there are some gems there. Including some comments from people who were apparently involved in developing Microsoft Word over the years. One of those commenters makes the claim that you can reliably read in current Word versions any files you may have created with earlier versions.
Reading that, I remembered an episode about ten years ago when Gisle Hannemyr asked for help on a mailing list we both subscribed to, for problems some ex-colleagues of his had accessing documentation of approximately 1998-1999 vintage.
The files had been created using whatever version of Microsoft Word was current at the time, but whatever version was current in 2003 was apparently either refusing to load the files or rendering them as complete gibberish. If I remember correctly, the problem was eventually solved by getting hold of a roughly same-vintage machine with an old Word version, loading the files and saving as RTF. That way, you would stand a fighting chance of preserving your work across versions (I've ranted about related matters earlier, read at your own peril).
At the time, I had several old versions of Word stashed away, including a possibly illicit copy of Word 5.0 for MS-DOS that I remembered keeping. I offered to help Gisle's colleagues of course, but as I remember they found a way to read their data without my help.
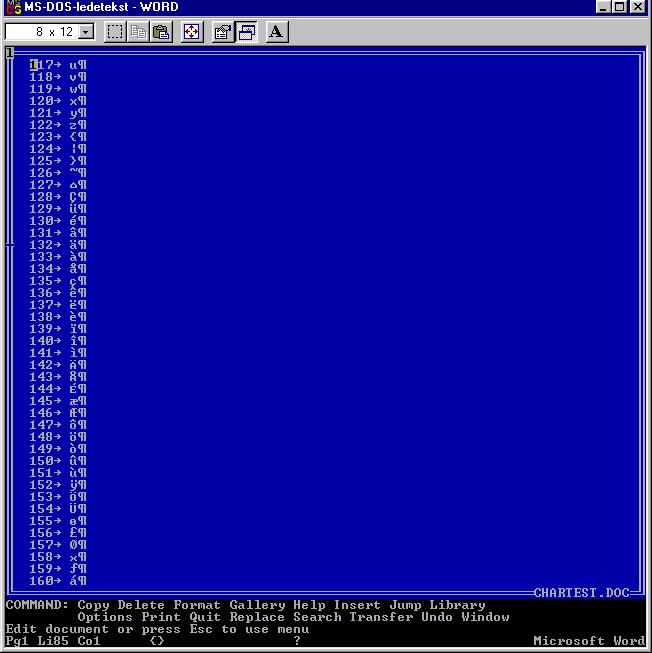
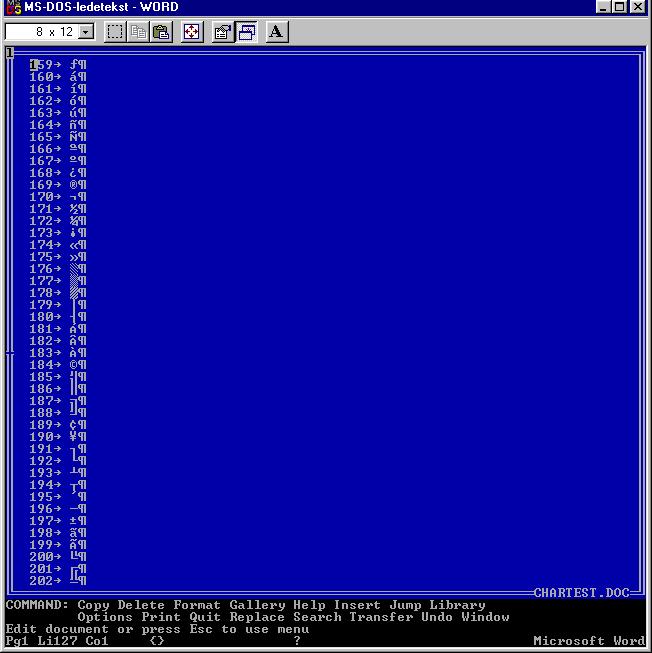
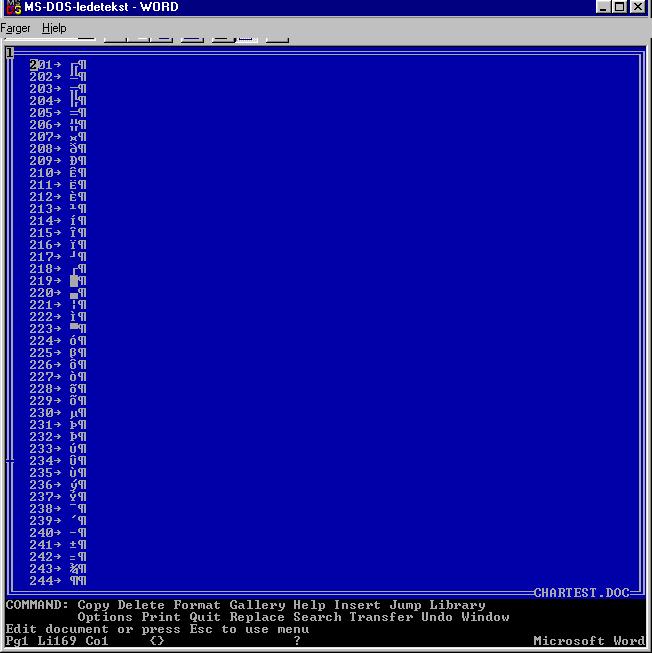
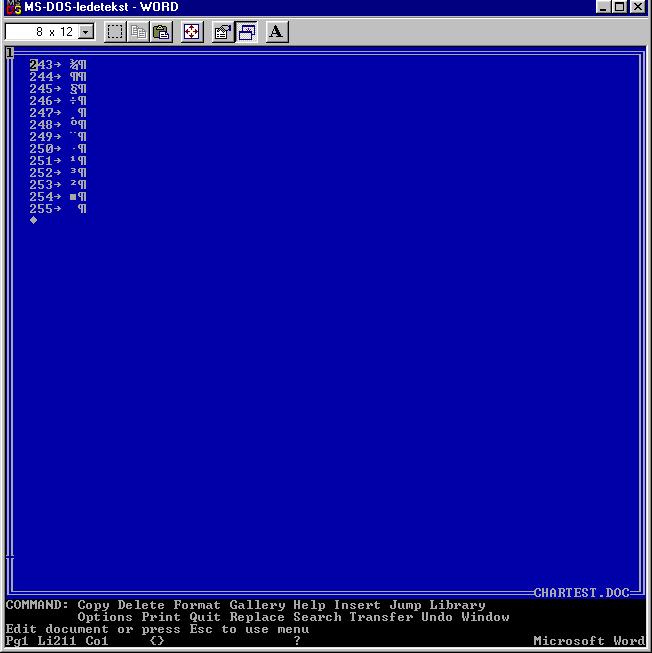
Anyway, when I looked in the program directory I must by then have copied across about a sequence of possibly a dozen different machines, there was also a copy of an extremely simple print test document, called CHARTEST.DOC. Do not click on that link unless you also have a copy of Microsoft Word for DOS around. It will be gibberish except for the sequence that represents an ASCII table.
Why this was interesting is probably better illustrated by the screen dump I made of the directory listing:

The document's time stamp, April 27, 1989, reminded me of a quick solution to an everyday need we had back then.
If you're old enough to remember MS-DOS code pages, you will understand why I found it necessary to generate an ASCII table for a print test.
The place I worked then was in the business of producing Norwegian and other Scandinavian language versions of software and related documentation. This was MS-DOS 3.something and Microsoft Windows 2.something era, when documentation came mainly in printed form, and to produce our camera-ready copy, we needed to make really sure that the machine was properly configured to make the Apple LaserWriter attached to its serial port produce copy that included the two characters IBM famously forgot when they created the initial IBM PC character set ('ø' and the uppercase version, 'Ø', which would otherwise appear on the printed page as cent and yen signs, respectively).
There were other characters we needed to see as well, some of them accessible in Word only by pressing and holding the Alt key while tapping a three-digit sequence on the numeric keypad.
My solution to the problem at hand was to generate a print sample of all printable ASCII characters, using a Turbo Pascal program that likely read something like this:
program chartest;
var
outfile : file;
c : byte;
begin
outfile := "chartest.txt"
for c := 0 to 255 do begin
if isprint(c) then
writeln(c, " = " chr(c), );
end;
end;
It's been almost that long (1989-ish) since I wrote any Turbo Pascal code, and like the other software I'm writing about in this article, I no longer have access to a copy, so there may well be syntax errors in that, but you will get the general idea.
My next step was to load the resulting file into Word, saving as Word's .DOC format, and we used that as a test print before any important Scandinavian-language document was to be printed. The program itself (likely called CHARTEST.PAS and possibly saved somewhere in the Turbo Pascal directory tree on my machine, or more likely too trivial to merit even saving once it had produced the output we wanted), does not survive. Neither does CHARTEST.TXT, but the .DOC file survives because I found it so useful I copied it to the Word program directory.
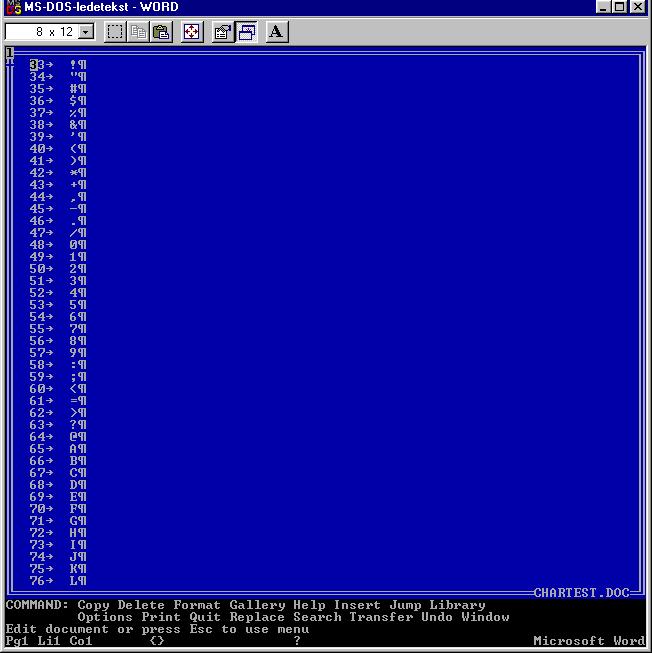
Then when Gisle's request came, and I still had a machine somewhere that had Microsoft Word 2000 on it, which was unable to read the file correctly, as the first screenshot shows:

(You can get the raw version from here)
My offer then to help convert probably means I still had other historical versions available at the time, but none of them survive in my archives today. (I left the company in 2008 after selling off my founder's share and was very careful to keep only what I had a clear right to keep).
The PDF file shows expected printer output as I prepared it back then, generated from the PostScript file which I assume is closer to the original date.
Compare the screenshots in the "winword" sequence, winword1.jpg, winword2.jpg, winword3.jpg, winword4.jpg, winword5.jpg, winword6.jpg with what the document looked like in the DOS version, wordscreen1.jpg, wordscreen2.jpg, wordscreen3.jpg, wordscreen4.jpg, wordscreen5.jpg and finally wordscreen6.jpg. You can find a particularly puzzling screenshot chartest-after-convpack.jpg here, with both programs showing an overlapping sequence, or you can grab all the files from here if you like.
The question that lingers in my mind is, when a simple character set table is not an obvious conversion, and a relatively close successor version was clearly unable to read the original file correctly, what other possibly content-deforming incompatibilites will come back to bite us when we need to go back to earlier material?
To my mind, flatly denying the problem like the commenters over at Charlie's blog purporting to be Microsoft insiders do will simply not do.
I invite your comments.
You might also be interested in reading selected pieces via That Grumpy BSD Guy: A Short Reading List (also here).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Opened your CHARTEST.DOC in MicroEmacs by JASSPA. There were a few characters of "junk" like this at the top:
ReplyDelete1¾«VS++++++> (but in the old IBM ascii characters). Then your table started with:
33 !
34 " etc.
The table looked good until 127-144 and 147-159 which display (on Windows XP) as a thick vertical bar.
145-146 display as single right-quote
160-255 are the various IBM symbols, followed by accented characters for various non-English languages.
The file ends with more "garbage":
€VSyµCH +
É . H@C+ H C:\WORD50\DOCS\*^,^0^5^:^>^" cm p10 p12 pt li C7 x ð\^^^a^d^h^l^o^1¾« €WSÿÿµCH +
É . H@C+ H C:\WORD50\DOCS\*^,^0^5^:^>^" cm p10 p12 pt li C7 x ð\^^^a^d^h^l^o^1¾« - +^v (0chartest4/3/89 07/07/88ÖC=HuHéæ=CuHé* = uHé =QuHé
‹F £#M‹F+‹V+£%M‰+'M‹F-‹V £)M‰++M‹F>£-M‹F+‹V+
I didn't use MS-Word back then, but it looks like MS didn't add much of a header or footer to the actual characters in the file. In other words, it should be possible to recover simple files (without extensive formatting) by opening with Emacs or other plain text editor.
I used FinalWord II back in the 80's, for many things including a 900 page textbook. Like you, I was able to generate Postscript (with some character substitutions for the PS Symbol font) and print my drafts on an Apple LaserWriter.
I think you should be able to recover your document just by using:
ReplyDelete"strings -n 2 CHARSET.doc" | head
I didn't check thoroughly, but antiword - the program I use for ".doc" files I recieve - seemingly did the job...
ReplyDelete