A DNSSEC book for the working sysadmin, likely to put you ahead of the pack in securing an essential Internet service.
I have a confession to make. Michael W. Lucas is a long time favorite of mine among tech authors. When Michael descends on a topic and produces a book, you can expect the result to contain loads of useful information, presented along with humor and real-life anecdotes so you will want to explore the topic in depth on your own systems.
In DNSSEC Mastery (apparently the second installment in what could become an extensive Mastery series -- the first title was SSH Mastery, reviewed here -- from Michael's own
Tilted Windmill Press), the topic is how to make your own contribution to making the Internet name service more reliable by having your own systems present verifiable, trustworthy information.
Before addressing the book itself, I'll spend some time explaining why this topic is important. The Domain Name System (usually referred to as DNS or simply 'the name service' even if nitpickers would be right that there is more than one) is one of the old-style Internet services that was created to solve a particluar set of problems (humans are a lot better at remembering names a than strings of numbers) in the early days of networking when security was not really a concern.
Old-fashioned DNS moves data via UDP, the connectionless no-guarantees-ever protocol mainly because the low protocol overhead in most cases means the answer arrives faster than it would have otherwise. Reliable delivery was sacrificed for speed, and in general, the thing just works. DNS is one of those things that makes the Internet usable for techies and non-techies alike.
The other thing that was sacrificed, or more likely never even considered important enough to care about at the time, was any hope of reliably verifying that the information received via the DNS service was in fact authentic and correct.
When you ask an application to look up a name, say you want to see if anything's new at bsdly.blogspot.com or if you want to send me mail to be delivered at bsdly.net, the answer comes back, not necessarily from the host that answers authoritatively for the domain, but more likely from the cache of a name server near you, and serves mainly one or more IP addresses, with no guarantee other than it is, indeed a record type that contains one or more IP addresses that appear to match your application's query.
Or to put it more bluntly, with traditional DNS, it's possible for a well positioned attacker to feed you falsfied information (ie leading your packets to somewhere they don't belong or to somewhere you never intended, potentially along with your confidential data), even if the original DNS designers appear to have considered the scenario rather unlikely back then in the nineteen-eighties.
With the realization that the Internet was becoming mainstream during the 1990s and that non-techies would rely on it for such things as banking services came support cryptographically enhanced versions of several of the protocols that take care of the bulk of Internet traffic payloads, and even the essential and mostly ignored (at least by non-techies) DNS protocol was enhanced several times over the years. Around the turn of the century came the RFCs that describe cryptographic signatures as part of the enhanced name service, and finally in 2005 the trio of RFCs (4033, 4034 and 4035) that form the core of the modern DNSSEC specification were issued.
But up until quite recently, most if not all DNSSEC implementations were either incomplete or considered experimental, and getting a working DNSSEC setup in place has been an admirable if rarely fulfilled ambition among already overworked sysadmins.
Then at what seems to be the exactly right moment, Michael W. Lucas publishes DNSSEC Mastery, which is a compact and and extremely useful guide to creating your own DNSSEC setup, avoiding the many pitfalls and scary manouvres you will find described in the HOWTO-style DNSSEC guides you're likely to encounter after a web search on the topic.
The book is aimed at the working sysadmin who already has at least basic operational knowledge of running a name service. Starting with one DNSSEC implementation that is known to be complete and functional (ISC BIND 9.9 -- Michael warns early on very clearly that earlier versions will not work -- if your favorite system doesn't have that packaged yet, you can build your own or start bribing or yelling at the relevant package maintainer), this book takes a very practical, hands on approach to its topic in a way that I think is well matched to the intended audience.
Keeping in mind that the one thing a working sysadmin is always short on is time, it is likely a strong advantage that this book is so compact. With 12 chapters, it comes in at just short of 100 pages in the PDF version I used for most of this review. With the stated requirement that the reader needs to be reasonably familiar with running a DNS service, the introductory chapters fairly quickly move on to give an overview of public key cryptography as it applies to DNSSEC, with pointers to wordier sources for those who would want to delve into details, before starting the steps involved in setting up secure name service using ISC BIND 9.9 or newer.
Always taking a practical approach, DNSSEC Mastery covers essentially all aspects of setting up and running a working service, including such topics as key management, configuring and debugging both authoritative and recursive resolvers, various hints for working with or around strengths or deficiencies in various client operating systems, how the new world of DNSSEC influences how you manage your zones and delegations, and did I mention debugging your setup? DNSSEC is a lot less forgiving of errors than your traditional DNS, and Michael includes both some entertaining examples and pointers to several useful resources for testing your work before putting it all into production. And for good measure, the final chapter demonstrates how to distribute data you would not trust to old fashioned DNS: ssh host key fingerprints and SSL certificates.
As I mentioned earlier, this title comes along at what seems to be the perfect time. DNSSEC use is not yet as widespread as it perhaps should be, in part due to incomplete implementations or lack of support in several widely used systems. The free software world is ahead of the pack, and just as the world is getting to realize the importance of a trustworthy Internet name service, this book comes along, aimed perfectly at the group of people who will need an accessible-to-techies book like this one. And it comes at a reasonable price, too. If you're in this book's target group, it's a recommended buy.
The ebook is available in several formats from Tilted Windmill Press, Amazon and other places. A printed version is in the works, but was not available at the time this review was written (May 11, 2013).
Note: Michael W. Lucas gives tutorials, too, like this one at BSDCan in Ottawa, May 15 2003.
Title: DNSSEC Mastery: Securing The Domain Name System With BIND
Author: Michael W. Lucas
Publisher: Tilted Windmill Press (April 2012)
Michael W. Lucas has another, somewhat chunkier book out this year too, Absolute OpenBSD, 2nd edition, a very good book about my favorite operating system. It would have been reasonable to expect a review here of that title too, except that I served as the book's technical editor, and as such a review would be somewhat biased.
But if you're interested in OpenBSD and haven't got your copy of that book yet, you're in for a real treat. If a firewall or other networking is closer to your heart, you could give my own The Book of PF and the PF tutorial (or here) it grew out of. You can even support the OpenBSD project by buying the books from them at the same time you buy your CD set, see the OpenBSD Orders page for more information.
Upcoming talks: I'll be speaking at BSDCan 2013, on The Hail Mary Cloud And The Lessons Learned. There will be no PF tutorial at this year's BSDCan, fortunately my staple tutorial item was crowded out by new initiatives from some truly excellent people. (I will, however, be bringing a few copies of The Book of PF and if things work out in time, some other items you may enjoy.)
Saturday, May 11, 2013
Tuesday, May 7, 2013
The Term Hackathon Has Been Trademarked In Germany. Now Crawl Back Under That Rock, Please.
Trademarking somebody else's idea behind their back is both a bad idea and highly immoral. If it wasn't your idea, you don't trademark and you don't patent. It really is that simple, people.
The news that the term hackathon had been trademarked in Germany reached me late last week, via this thread on openbsd-misc. The ideas sounded pretty ludicrous to me at the time, but I was too busy with other stuff that couldn't wait to start reacting properly, and a few distractions later, I'd forgotten about the whole thing.
Then today, via the Twitter stream, came the news that an outfit trading under the name Young Targets (how cute) had now started sending invoices at EUR 2500 a pop to anybody in Germany who dared use the term. One example has been preserved here by Hannover-based doctape, who had hosted an informal developer meetup earlier this year.
It may come as a surprise to a select few, but if there is somebody, somewhere, who is entitled to making money off that fairly well-known term, it is not that group of Germans. The term hackathon has been in use for a decade at least, and it springs like many other good things from the free software movement. The exact origin of the term is not clear, but one of the more prominent contenders for the first original use is the OpenBSD project. As you can see from the project's hackathons page, informal developer gatherings have most likely been called just that since 1999 at least.
And as anyone with an Internet connection an minimal searching skills will find out, hackathons have been quite crucial in keeping the project moving forward and offering tech goodies everybody uses, all for free and under a permissive license anybody can understand.
These items include the Secure Shell client and server used by 97% of the Internet (OpenSSH), the much praised OpenBSD packet filter PF and a whole host of other useful software that's developed as integral parts of the OpenBSD system but tend to find their way into other products such as those offered by Apple, Blackberry and quite a few others, including Linux distributions.
My brief and not too exhaustive search of mailing list archives tonight seems to turn up this message From Theo de Raadt to openbsd-misc dated July 1st, 2001 as the earliest public reference to a hackathon, but reading Theo's message again today I'm pretty convinced that the term was in common use even back then. If anyone can come up with evidence of use earlier than this, I'd love to hear from you, of course (mail to peter at bsdly dot net preferably with the word hackathon somewhere in the subject will be read with interest, or leave a comment below if you prefer).
I'm no lawyer at the best of times, but trademarking a term that both originated elsewhere and has been in general use for more than a decade seems to me at least highly immoral, and if it's not illegal, it should be. Trademarking a free software term and proceeding to charge EUR 2500 a pop for its use? It will be in your best interest to stay out of my physical proximity, Meine Damen und Herren.
Hot on the heels of what must have been a hectic night for the newly targeted young Berliners comes an announcement that states that they kinda, sorta will consider not charging sufficiently non-profity people for the use anyway, in the fluffiest terms I have ever heard come out of a German.
I'll offer our new targets some practical advice: Stop your nonsense right now, and make a real effort to track down the originators of the hackathon concept. It's likely you wil find that person is either Theo de Raadt or somebody else closely associated with the OpenBSD about the last turn of the century. If you cannot unregister the trademark, transfer the rights, free of charge, to the concept's originator.
Then either return any fees collected from your wrongful registration, or, at your victims' option, donate the equivalent sum to OpenBSD or a charity of your individual victims' choice.
Doing the right thing this late in the game and after messing up this thoroughly most likely won't save you from being the target of some sort of mischief from young hotheads (note that I strongly caution against using extra-legal tactics in this matter), but at least you, members and employees of Young Targets can hope that this embarrasing episode will be forgotten soon enough for you to resume some semblance of carreers in a not too distant future. Please go hide under a rock for now, after you've done the right thing as outlined above.
For anyone else interested in the matter, I strongly urge you to go to the OpenBSD project's donations page to donate, grab some CD sets and/or other swag from the orders page, and if you think you can help out with one or more items listed on the hardware wanted page, that will be very welcome for the project too.
It should be noted that I do not serve in any official capacity for the OpenBSD project. The paragraphs above represent my opinion only, and what I have outlined here should not be considered any kind of offer or representation on behalf of the OpenBSD project.
If you're interested in OpenBSD in general, you have a real treat coming up in the form of Michael W. Lucas' Absolute OpenBSD, 2nd edition. If a firewall or other networking is closer to your heart, you could give my own The Book of PF and the PF tutorial (or here) it grew out of. You can even support the OpenBSD project by buying the books from them at the same time you buy your CD set, see the OpenBSD Orders page for more information.
Upcoming talks: I'll be speaking at BSDCan 2013, on The Hail Mary Cloud And The Lessons Learned, with a preview planned for the BLUG meeting a couple of weeks before the conference. There will be no PF tutorial at this year's BSDCan, fortunately my staple tutorial item was crowded out by new initiatives from some truly excellent people. (I will, however, be bringing a few copies of The Book of PF and if things work out in time, some other items you may enjoy.)
The news that the term hackathon had been trademarked in Germany reached me late last week, via this thread on openbsd-misc. The ideas sounded pretty ludicrous to me at the time, but I was too busy with other stuff that couldn't wait to start reacting properly, and a few distractions later, I'd forgotten about the whole thing.
Then today, via the Twitter stream, came the news that an outfit trading under the name Young Targets (how cute) had now started sending invoices at EUR 2500 a pop to anybody in Germany who dared use the term. One example has been preserved here by Hannover-based doctape, who had hosted an informal developer meetup earlier this year.
It may come as a surprise to a select few, but if there is somebody, somewhere, who is entitled to making money off that fairly well-known term, it is not that group of Germans. The term hackathon has been in use for a decade at least, and it springs like many other good things from the free software movement. The exact origin of the term is not clear, but one of the more prominent contenders for the first original use is the OpenBSD project. As you can see from the project's hackathons page, informal developer gatherings have most likely been called just that since 1999 at least.
And as anyone with an Internet connection an minimal searching skills will find out, hackathons have been quite crucial in keeping the project moving forward and offering tech goodies everybody uses, all for free and under a permissive license anybody can understand.
These items include the Secure Shell client and server used by 97% of the Internet (OpenSSH), the much praised OpenBSD packet filter PF and a whole host of other useful software that's developed as integral parts of the OpenBSD system but tend to find their way into other products such as those offered by Apple, Blackberry and quite a few others, including Linux distributions.
My brief and not too exhaustive search of mailing list archives tonight seems to turn up this message From Theo de Raadt to openbsd-misc dated July 1st, 2001 as the earliest public reference to a hackathon, but reading Theo's message again today I'm pretty convinced that the term was in common use even back then. If anyone can come up with evidence of use earlier than this, I'd love to hear from you, of course (mail to peter at bsdly dot net preferably with the word hackathon somewhere in the subject will be read with interest, or leave a comment below if you prefer).
I'm no lawyer at the best of times, but trademarking a term that both originated elsewhere and has been in general use for more than a decade seems to me at least highly immoral, and if it's not illegal, it should be. Trademarking a free software term and proceeding to charge EUR 2500 a pop for its use? It will be in your best interest to stay out of my physical proximity, Meine Damen und Herren.
Hot on the heels of what must have been a hectic night for the newly targeted young Berliners comes an announcement that states that they kinda, sorta will consider not charging sufficiently non-profity people for the use anyway, in the fluffiest terms I have ever heard come out of a German.
I'll offer our new targets some practical advice: Stop your nonsense right now, and make a real effort to track down the originators of the hackathon concept. It's likely you wil find that person is either Theo de Raadt or somebody else closely associated with the OpenBSD about the last turn of the century. If you cannot unregister the trademark, transfer the rights, free of charge, to the concept's originator.
Then either return any fees collected from your wrongful registration, or, at your victims' option, donate the equivalent sum to OpenBSD or a charity of your individual victims' choice.
Doing the right thing this late in the game and after messing up this thoroughly most likely won't save you from being the target of some sort of mischief from young hotheads (note that I strongly caution against using extra-legal tactics in this matter), but at least you, members and employees of Young Targets can hope that this embarrasing episode will be forgotten soon enough for you to resume some semblance of carreers in a not too distant future. Please go hide under a rock for now, after you've done the right thing as outlined above.
For anyone else interested in the matter, I strongly urge you to go to the OpenBSD project's donations page to donate, grab some CD sets and/or other swag from the orders page, and if you think you can help out with one or more items listed on the hardware wanted page, that will be very welcome for the project too.
It should be noted that I do not serve in any official capacity for the OpenBSD project. The paragraphs above represent my opinion only, and what I have outlined here should not be considered any kind of offer or representation on behalf of the OpenBSD project.
If you're interested in OpenBSD in general, you have a real treat coming up in the form of Michael W. Lucas' Absolute OpenBSD, 2nd edition. If a firewall or other networking is closer to your heart, you could give my own The Book of PF and the PF tutorial (or here) it grew out of. You can even support the OpenBSD project by buying the books from them at the same time you buy your CD set, see the OpenBSD Orders page for more information.
Upcoming talks: I'll be speaking at BSDCan 2013, on The Hail Mary Cloud And The Lessons Learned, with a preview planned for the BLUG meeting a couple of weeks before the conference. There will be no PF tutorial at this year's BSDCan, fortunately my staple tutorial item was crowded out by new initiatives from some truly excellent people. (I will, however, be bringing a few copies of The Book of PF and if things work out in time, some other items you may enjoy.)
Saturday, May 4, 2013
Keep smiling, waste spammers' time
When you're in the business of building the networks people need and the services they need to run on them, you may also be running a mail service. If you do, you will sooner or later need to deal with spam. This article is about how to waste spammers' time and have a good time while doing it.
Assembling the parts
To take part of the fun and useful things in this article, you need a system with PF, the OpenBSD packet filter. If you're reading this magazine you are likely to be running all important things on a BSD already, and all the fully open source BSDs by now include PF (as do the commercialized variants sold by the Apple and Blackberry), developed by OpenBSD but also ported to the other BSDs. On OpenBSD, it's the packet filter, and if you're running FreeBSD, NetBSD or DragonFlyBSD it's likely to be within easy reach, either as a loadable kernel module or as a kernel compile-time option.
Getting started with PF is surprisingly easy. The official documentation such as the PF FAQ is very comprehensive, but you may be up and running faster if you buy The Book of PF or do what more than 200,000 others have done before you: Download or browse the free forerunner from http://home.nuug.no/~peter/pf. Or do both, if you like.
Network design issues
A PF setup can be, and to my mind should be, quite unobtrusive. For the activities in this article it does not matter much where you run your PF filtering, as long as it is somewhere in the default path of your incoming SMTP traffic. A gateway with PF is usually an excellent choice, but if it suits your needs better, it is quite feasible to do the filtering needed for this article on the same host your SMTP server runs.
Enter spamd
OpenBSD's spamd, the spam deferral daemon (not to be confused with the program with the same name from the SpamAssassin content filtering system), first appeared in OpenBSD 3.3. The original spamd was a tarpitter with a very simple mission in life. Its spamd-setup(8) program would take a list of known bad IP addresses, that is, the IP addresses of machines known to have sent spam recently, and load it into a table. The main spamd(8) program would then have any SMTP traffic from hosts in that table redirected to it, and spamd would answer those connections s-l-o-w-l-y, by default one byte per second.
A minimal PF config
As man spamd will tell you, the bare minimum to get spamd running in a useful mode on systems with PF version 4.1 or later is
Note: When you get around to upgrading to OpenBSD 5.8, you will need to do a quick search and replace to turn the rdr-to occurences in those rules into divert-tos instead. That mechanism is slightly more efficient for local use (but this also means that the spamd you're using has to be on the local machine).
Or, in the pre-OpenBSD 4.7 syntax still in use on some systems,
This means, essentially, that any smtp traffic from hosts that are not already in the table spamd-white will be redirected to localhost, port spamd, where you have set up the spam deferral daemon spamd to listen for connections. Enabling spamd, on the other hand, is as easy as adding spamd_flags="" to your /etc/rc.conf.local if you run OpenBSD or /etc/rc.conf if you run FreeBSD (Note that on FreeBSD, spamd is a port, so you need to install that before proceeding. Also, on recent FreeBSDs, the rc.conf lines are obspamd_enable="YES" to enable spamd and obspamd_flags="" to set any further flags.), and starting it with
or if you are on FreeBSD,
In the following examples we will use the OpenBSD-originated doas(1) command to prefix operations that require elevated privileges. If your system does not include doas, you can in almost all cases use sudo instead
It is also worth noting that if you add the "-d" for Debug flag to your spamd flags, spamd will generate slightly more log information, of the type shown in the log excerpts later in this article.
While earlier versions of spamd required a slightly different set of redirection rules and ran in blacklists-only mode by default, spamd from OpenBSD 4.1 onwards runs in greylisting mode by default. Let's have a look at what greylisting means and how it differs from other spam detection techniques before we exlore the finer points of spamd configuration.
Content versus behavior: Greylisting
When the email spam deluge started happening during the late 1990s and early 2000s, observers were quick to note that the messages in at least some cases messages could be fairly easily classified by looking for certain keywords, and the bulk of the rest fit well in familiar patterns.
Various kinds of content filtering have stayed popular and are the mainstays of almost all proprietary and open source antispam products. Over the years the products have develped from fairly crude substring match mechanisms into multi-level rule based systems that incorporate a number of sophisticated statistical methods. Generally the products are extensively customizable and some even claim the ability to learn based on the users' preferences.
Those sophisticated and even beautiful algorithms do have a downside, however: For each new trick a spam producer chooses to implement, the content filtering becomes incrementally more complex and computationally expensive.
In sharp contrast to the content filtering, which is based on message content, greylisting is based on studying spam senders' behavior on the network level. The 2003 paper by Evan Harris noted that the vast majority of spam appeared to be sent by software specifically developed to send spam messages, and those systems typically operated in a 'fire and forget' mode, only trying to deliver each message once.
The delivery software on real mail servers, however, are proper SMTP implementations, and since the relevant RFCs state that you MUST retry delivery in case you encounter some classes of delivery errors, in almost all cases real mail servers will retry 'after a reasonable amount of time'.
Spammers do not retry. So if we set up our system to say essentially
- we should be getting rid of anything the sending end does not consider important enough to retry delivering.
The practical implementation is to record for each incoming delivery attempt at least
The first release of OpenBSD's spamd to support greylisting was OpenBSD 3.5. spamd's greylisting implementation operates only on individual IP addresses, and by default sets the minimum time before a delivery attempt passes to 25 minutes, the time to live for a greylist entry to 4 hours, while a whitelisted entry stays in the whitelist for 36 days after the delivery of the last message from that IP address. With a properly configured setup, machines that receive mail from your outgoing mail servers will automatically be whitelisted, too.
The great advantage to the greylisting approach is that mail sent from correctly configured mail servers will be let through. New correspondents will experience an initial delay for the first message to get through and their IP address is added to the whitelist. The initial delay will vary depending on a combination of the length of your minimum time before passing and the sender's retry interval. Regular correpondents will find that once they have cleared the initial delay, their IP addresses are kept in the whitelist as long as email contact is a regular affair.
And the technique is amazingly effective in removing spam. 80% to 95% or better reduction in the number of spam messages is frequently cited, but unfortunately only a few reports with actual numbers have been published. An often-cited report is Steve Williams' message on opensd-misc (available among other places at marc.info), where Steve describes how he helped a proprietary antispam device cope with an unexptected malware attack. He notes quite correctly that the blocked messages were handled without receiving the message body, so their apparently metered bandwidth use was reduced.
Even after more than four years, greylisting remains extremely effective. Implementing greylisting greatly reduces the load on your content filtering systems, but since messages sent by real mail servers will be let through, it will sooner or later also let a small number of unwanted messages through, and unfortunately it does not eliminate the need for content filtering altogether. Unfortunately you will still occasionally encounter some sites that do not play well with greylisting, see the references for tips on how to deal with those.
Do we need blacklists?
With greylisting taking care of most of the spam, is there still a place for blacklists? It's a fair question. The answer depends in a large part on how the blacklists you are considering are constructed and how much you trust the people who generate them and the methods they use.
The theory behind all good blacklists is that once an IP address has been confirmed as a source of spam, it is unlikely that there will be any valid mail send from that IP address in the foreseeable future.
With a bit of luck, by the time the spam sender gets around to trying to deliver spam to addresses in your domain, the spam sender will already be on the blacklist and will in turn treated to the s-l-o-w SMTP dialogue.
Knowing how a host makes it into a blacklist is important, but a clear policy for checking that the entries are valid and for removing entries is essential too. Once spam senders are detected, it is likely that their owners will do whatever it takes to stop the spam sending. Another reason to champion 'aggressive maintenance' of blacklists is that it is likely that IP addresses are from time to time reassigned, and some ISPs do in fact not guarantee that a certain physical machine will be assigned the same IP address the next time it comes online.
Your spamd.conf file contains a few suggested blacklists. You should consider carefully which ones to use. Take the time you need to look up the web pages listed in the list descriptions in the spamd.conf file and then decide which lists fit your needs. If you decide to use one or more blacklists, edit your spamd.conf to include those and set up a cron job to let spamd-setup load updated blacklists at regular intervals.
The lists I consider the more interesting ones are the nixspam list, with a 4 day expiry, and the uatraps list, with a 24-hour exiry. The nixspam list is maintained by ix.de, based on their logs of hosts that have verifiably sent spam to their mail servers. The uatraps list is worth looking into too, mainly because it is generated automatically by greytrapping.
Behavior based response: Greytrapping
Greytrapping is yet another useful technique that grew out of hands-on empirical study of spammer behavior, taken from the log data available at ordinary mail servers. You have probably seen spam messages offering lists of "millions of verified email addresses" available. However, verification goes only so far. You can get a reasonable idea of the quality of that verification if you take some time to actually browse mail server logs for failed deliveries to addresses in your domain. In most cases you will find a number of attempts at delivering to addresses that either have never existed or at least have no valid reason to receive mail.
The OpenBSD spamd developers saw this too. They also realized that what addresses are deliverable or not in your own domain is something you have complete control over, and they formulated the following rule to guide a new feature to be added to spamd:
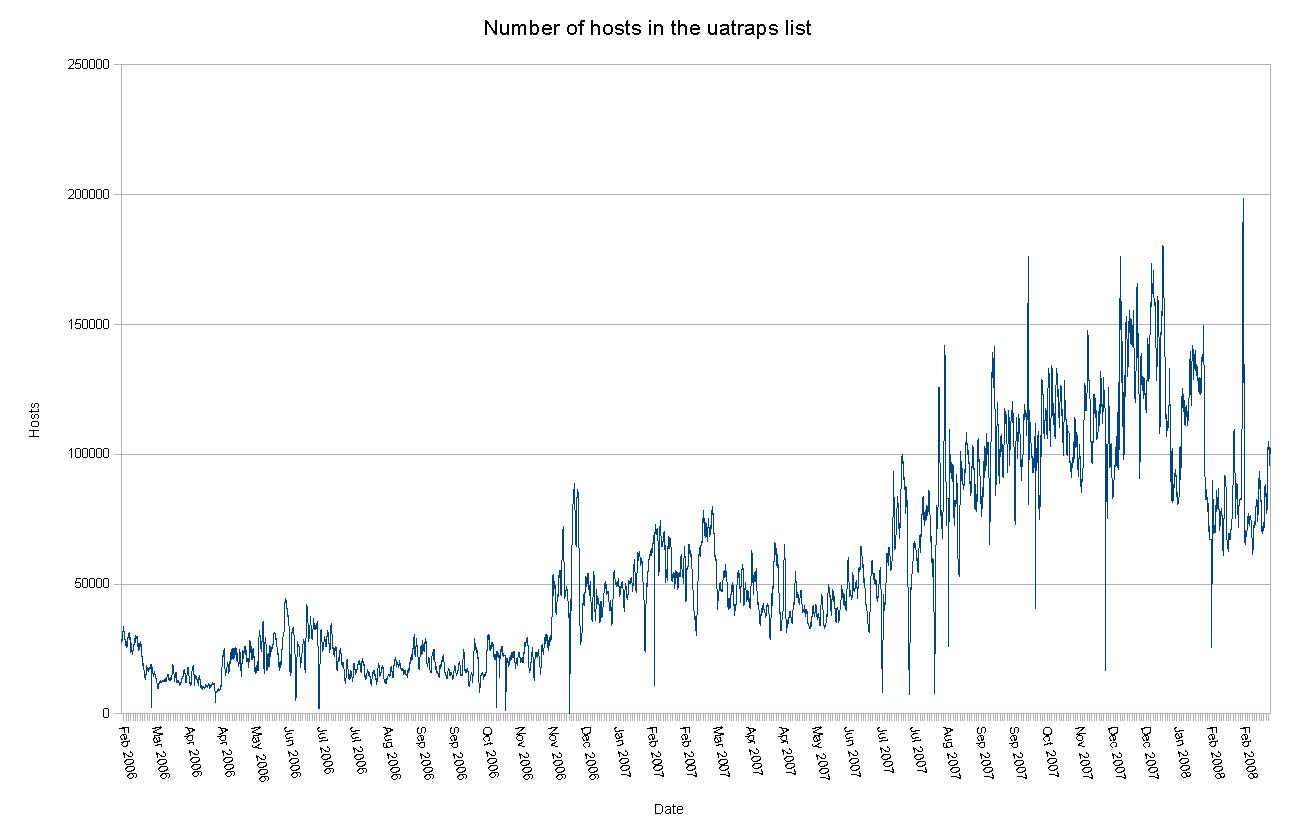
This is the way the uatraps list is generated. Bob Beck put a list of addresses he has referred to as 'ghosts of usenet postings past' on his local greytrap list, and started exporting the IP addresses he collects automatically to a freely available blacklist. As far as I know Bob has never published the list of email addresses in his spamtrap list, but the machines at University of Alberta appear to be targeted by enough spammers to count. At the time this article was written, the uatraps list typically contained roughly 120,000 addresses, and the highest number of addresses I have seen reported by my spamd-setup was just over 180,000 (it peaked later at just over 670,000 addresses). See Figure 1 for a graphical representation of the number of hosts in the uatraps list over the period February 2006 through early March 2008.

By using a well maintained blacklist such as the uatraps list you are likely to add a few more percentage points to the amount of spam stopped before it reaches your content filtering or your users, and you can enjoy the thought of actively wasting spammers' time.
A typical log excerpt for a blacklisted host trying to deliver spam looks like this:
Jan 16 19:55:50 skapet spamd[27153]: 82.174.96.131: connected (3/2), lists: uatraps Jan 16 19:59:33 skapet spamd[27153]: (BLACK) 82.174.96.131: <bryonRoe@boxerdelasgargolas.com> -> <schurkoxektk@ehtrib.org>
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: From: "bryon Roe" <bryonRoe@boxerdelasgargolas.com>
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: To: schurkoxektk@ehtrib.org
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: Subject: vresdiam
Jan 16 20:02:33 skapet spamd[27153]: 82.174.96.131: disconnected after 403 seconds. lists: uatraps
This particular spammer hung around at a rate of 1 byte per second for 403 seconds (six minutes, forty-three seconds), going through the full dialogue all the way up to the DATA part before my spamd rejected the message back to the spammer's queue.

That is a fairly typical connection length for a blacklisted host. Statistics from my sites (see Figure 2) show that most connections to spamd last from 0 to 3 seconds, a few hang on for about 10 seconds, and the next peak is at around 400 seconds. Then there's a very limited number that hang around for anywhere from 30 minutes to several hours, but those are too rare to be statistically significant (and damned near impossible to graph sensibly in relation to the rest of the data.
Interaction with a running spamd: spamdb
Your main interface to the contents of your spamd related data is the spamdb administration program. The command
without any parameters will give you a complete listing of all entries in the database, whether WHITE, GREY or others. In addition, the program supports a number of different operations on entries in spamd's data, such as adding or deleting entries or changing their status in various ways. For example,
will add the host 192.168.110.12 to your spamd's whitelist or update its status to WHITE if there was an entry for that address in the database already. Conversely, the command
will delete the entry for that IP address from the database.
For greytrapping purposes, you can add or delete spamtrap email addresses by using a command such as
to add that address to your list of spamtrap addresses. To remove the address, you substitute -d for the -a. The -t flag lets you add or delete entries for TRAPPED addresses manually.
Hitting back, poisoning their well: Summary of my field notes
Up util July 2007, I ran my spamd installations with greylisting, supplemented by hourly updates of the uatraps blacklist and a small local list of greytrapping addresses like the one in the previous section, which is obviously a descendant of a message-id, probably harvested from a news spool or from some unfortunate malware victim's mailbox. Then something happened that made me take a more active approach to my greytrapping.
My log summaries showed me an unusually high number of attempted deliveries to non-existent addresses in the domains I receive mail for. Looking a little closer at the actual logs showed spam backscatter: Somebody, somewhere had sent a large number of messages with made up addresses in one of our domains as the From: or Reply-to: addresses, and in those cases the to: address wasn't deliverable either, the bounce messages were sent back to our servers.
The fact that they were generating bounces to the spam messages indicates that any copies of those messages directed at actually deliverable addresses in those domains would have been delivered to actual users' mailboxes, not too admirable in itself.
Another variety that showed up when I browsed the spamd logs was this type:
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: Subject: Considered UNSOLICITED BULK EMAIL, apparently from you
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: From: "Content-filter at srv77.kit.kz" <postmaster@srv77.kit.kz>
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: To: <skulkedq58@datadok.no>
which could only mean that the administrators at that system had not yet learned that spammers no longer use their own From: addresses.
Roughly at that time it struck me:
(Actually in the first discussions about this with my BLUG user group friends, we referred to this as 'brønnpissing' in Norwegian, which translates as 'urinating in their well'. The more detailed descriptions of the various steps in the process can be tracked via blog entries at http://bsdly.blogspot.com, starting with the entry dated Monday, July 9th, 2007, Hey, spammer! Here's a list for you!.)
Over the following weeks and months I collected addresses from my logs and put them on the web page at http://www.bsdly.net/~peter/traplist.shtml.
After a while, I determined that harvesting the newly generated soon-to-be-spamtrap addresses directly from our greylist data was more efficient and easier to script than searching the mail server logs. Using spamdb, you can extract the current contents of the greylist with
which produces output in the format
GREY|96.225.75.144|Wireless_Broadband_Router|<aguhjwilgxj@bn.camcom.it>|<bsdly@bsdly.net>|1198745212|1198774012|1198774012|1|0
GREY|206.65.163.8|outbound4.bluetie.com|<>|<leonard159@datadok.no>|1198752854|1198781654|1198781654|3|0
GREY|217.26.49.144|mxin005.mail.hostpoint.ch|<>|<earle@datadok.no>|1198753791|1198782591|1198782591|2|0
where GREY is what you think it is, the IP address is the sending host's address, the third entry is what the sender identified as in the SMTP dialogue (HELO/EHLO), the fourth is the From: address, the fifth is the To: address. The next three are date values for first contact, when the status will change from GREY to WHITE and when the entry is set to expire, respectively. The final two fields are the number of times delivery has been blocked from that address and the number of conntections passed for the entry.
For our purpose, extracting the made up To: addresses in our domains from backscatter bounces, it is usually most efficient to search for the "<>" indicating bounces, then print the fifth field. Or, expressed in grep and awk:
$ doas spamdb | grep "<>" | awk -F\| '{print $5}' | tr -d '<>' | sort | uniq
will give you a sorted list of unique intended bounce-to addresses, in a format ready to be fed to a corresponding script for feeding to spamd. The data above and the command line here would produce
- in some situations, the list will be a tad longer than in this ilustration. This does not cover the cases where the spammers apparently assume that any mail with From: addresses in the local domain will go through, even when they come from elsewhere. Extracting the fourth column instead
# spamdb | grep GREY | awk -F\| '{print $4}' | grep mydomain.tld | tr -d '<>' | sort | uniq
will give you a list of From: addresses in your own domain to weed out a few more bad ones from.
After a while, I started seeing very visible and measurable effects. At short intervals, we see spam runs targeting the addresses in the published list, working their way down in more or less alphabetical order. For example, in my field notes dated November 25, 2007, I noted
It is also worth noting that even a decreipt the Pentium III 800MHz (since replaced with a Pentium 4 box, donations of more recent hardware gratefully accepted) at the end of the unexciting DSL line to my house has been able to handle about 190 simultaneous connections from TRAPPED addresses without breaking into a sweat. For some odd reason, the number of simultaneous connection a the other sites I manage with better bandwidth have not been as high as the ones from my home gateway.
During the months I've been running the trapping experiment, the number of spamtrap addresses in the published list has grown to more than 10,000 addresses (by May 4th, 2013, the list had grown to 24431 entries). Oddly enough, my greylist scans still show up a few more every few days.
Meanwhile, my users report that spam in their mailboxes is essentially non-existent. On the other side of the fence, there are indications that it may have dawned on some of the spammers that generating random addresses in other people's domains might end up poisoning their own well, so they started introducing patterns to be able to weed out their own made up addresses from their lists. I take that as a confirmation that our harvesting and republishing efforts have been working rather well.
The method they use is to put some recognizable pattern into the addresses they generate. One such pattern is to take the victim domain name, prepend "dw" and append "m" to make up the local part and then append the domain, so starting from sia.com we get dwsiam@sia.com.
There is one other common variation on that theme, where the prepend string is "lin" and the append string is "met", producing addresses like linhrimet@hri.de. Then again when they use that new, very recognizable, address to try to spam my spamtrap address malseeinvmk@bsdly.net, another set of recognition mechanisms are activated, and the sending machine is quietly added to my spamd-greytrap. (We've since seen other patterns come and go, scanning the list at http://www.bsdly.net/~peter/traplist.shtml will see examples of them all).
And finally, there are clear indications that spammers use slightly defective relay checkers that tend to conclude that a properly configured spamd is an open relay, swelling my greylists temporarily. We already know that the spammers do not use From: addresses they actually receive mail for, and consequently they will never know that those messages were in fact never delivered.
If you've read this far and you're still having fun, you can find other anecdotes I would have had a hard time believing myself a short time back in my field notes at bsdly.blogspot.com. By the time the magazine has been printed and distributed (or by the time you find this revised article online), there might even be another few tall tales there.
You might also want to read
The Book of PF, 4th Edition, by Peter N. M. Hansteen, No Starch Press 2026 (covers both pre-4.7 and post-4.7 syntax), available in better bookshops or from the publisher
The Next Step in the Spam Control War: Greylisting, by Evan Harris. Available at http://greylisting.org/articles/whitepaper.shtml
Maintaining A Publicly Available Blacklist - Mechanisms And Principles, April 14, 2013 describes the maintenance regime for the published version of my spamd-greytrap list
In The Name Of Sane Email: Setting Up OpenBSD's spamd(8) With Secondary MXes In Play - A Full Recipe, May 28, 2012, offers another, more OpenBSD-centric, recipe for setting up a spamd based system.
This article originally appeared in BSD Magazine #2, June 2008. This re-publication has suffered only minor updates and edits.
If you're interested in OpenBSD in general, you have a real treat coming up in the form of Michael W. Lucas' Absolute OpenBSD, 2nd edition. If a firewall or other networking is closer to your heart, you could give my own The Book of PF and the PF tutorial (or here) it grew out of. You can even support the OpenBSD project by buying the books from them at the same time you buy your CD set, see the OpenBSD Orders page for more information.
Upcoming talks: I'll be speaking at BSDCan 2013, on The Hail Mary Cloud And The Lessons Learned, with a preview planned for the BLUG meeting a couple of weeks before the conference. There will be no PF tutorial at this year's BSDCan, fortunately my staple tutorial item was crowded out by new initiatives from some truly excellent people.
Assembling the parts
To take part of the fun and useful things in this article, you need a system with PF, the OpenBSD packet filter. If you're reading this magazine you are likely to be running all important things on a BSD already, and all the fully open source BSDs by now include PF (as do the commercialized variants sold by the Apple and Blackberry), developed by OpenBSD but also ported to the other BSDs. On OpenBSD, it's the packet filter, and if you're running FreeBSD, NetBSD or DragonFlyBSD it's likely to be within easy reach, either as a loadable kernel module or as a kernel compile-time option.
Getting started with PF is surprisingly easy. The official documentation such as the PF FAQ is very comprehensive, but you may be up and running faster if you buy The Book of PF or do what more than 200,000 others have done before you: Download or browse the free forerunner from http://home.nuug.no/~peter/pf. Or do both, if you like.
Network design issues
A PF setup can be, and to my mind should be, quite unobtrusive. For the activities in this article it does not matter much where you run your PF filtering, as long as it is somewhere in the default path of your incoming SMTP traffic. A gateway with PF is usually an excellent choice, but if it suits your needs better, it is quite feasible to do the filtering needed for this article on the same host your SMTP server runs.
Enter spamd
OpenBSD's spamd, the spam deferral daemon (not to be confused with the program with the same name from the SpamAssassin content filtering system), first appeared in OpenBSD 3.3. The original spamd was a tarpitter with a very simple mission in life. Its spamd-setup(8) program would take a list of known bad IP addresses, that is, the IP addresses of machines known to have sent spam recently, and load it into a table. The main spamd(8) program would then have any SMTP traffic from hosts in that table redirected to it, and spamd would answer those connections s-l-o-w-l-y, by default one byte per second.
A minimal PF config
As man spamd will tell you, the bare minimum to get spamd running in a useful mode on systems with PF version 4.1 or later is
table <spamd-white> persist
table <nospamd> persist file "/etc/mail/nospamd"
pass in on egress proto tcp from any to any port smtp \
rdr-to 127.0.0.1 port spamd
pass in on egress proto tcp from <nospamd> to any port smtp
pass in log on egress proto tcp from <spamd-white> to any port smtp
pass out log on egress proto tcp to any port smtp
Note: When you get around to upgrading to OpenBSD 5.8, you will need to do a quick search and replace to turn the rdr-to occurences in those rules into divert-tos instead. That mechanism is slightly more efficient for local use (but this also means that the spamd you're using has to be on the local machine).
Or, in the pre-OpenBSD 4.7 syntax still in use on some systems,
table <spamd-white> persist
table <nospamd> persist file "/etc/mail/nospamd"
no rdr inet proto tcp from <spamd-white> to any \
port smtp
rdr pass inet proto tcp from any to any \
port smtp -> 127.0.0.1 port spamd
This means, essentially, that any smtp traffic from hosts that are not already in the table spamd-white will be redirected to localhost, port spamd, where you have set up the spam deferral daemon spamd to listen for connections. Enabling spamd, on the other hand, is as easy as adding spamd_flags="" to your /etc/rc.conf.local if you run OpenBSD or /etc/rc.conf if you run FreeBSD (Note that on FreeBSD, spamd is a port, so you need to install that before proceeding. Also, on recent FreeBSDs, the rc.conf lines are obspamd_enable="YES" to enable spamd and obspamd_flags="" to set any further flags.), and starting it with
$ doas /usr/libexec/spamd
or if you are on FreeBSD,
$ sudo /usr/local/libexec/spamd
In the following examples we will use the OpenBSD-originated doas(1) command to prefix operations that require elevated privileges. If your system does not include doas, you can in almost all cases use sudo instead
It is also worth noting that if you add the "-d" for Debug flag to your spamd flags, spamd will generate slightly more log information, of the type shown in the log excerpts later in this article.
While earlier versions of spamd required a slightly different set of redirection rules and ran in blacklists-only mode by default, spamd from OpenBSD 4.1 onwards runs in greylisting mode by default. Let's have a look at what greylisting means and how it differs from other spam detection techniques before we exlore the finer points of spamd configuration.
Content versus behavior: Greylisting
When the email spam deluge started happening during the late 1990s and early 2000s, observers were quick to note that the messages in at least some cases messages could be fairly easily classified by looking for certain keywords, and the bulk of the rest fit well in familiar patterns.
Various kinds of content filtering have stayed popular and are the mainstays of almost all proprietary and open source antispam products. Over the years the products have develped from fairly crude substring match mechanisms into multi-level rule based systems that incorporate a number of sophisticated statistical methods. Generally the products are extensively customizable and some even claim the ability to learn based on the users' preferences.
Those sophisticated and even beautiful algorithms do have a downside, however: For each new trick a spam producer chooses to implement, the content filtering becomes incrementally more complex and computationally expensive.
In sharp contrast to the content filtering, which is based on message content, greylisting is based on studying spam senders' behavior on the network level. The 2003 paper by Evan Harris noted that the vast majority of spam appeared to be sent by software specifically developed to send spam messages, and those systems typically operated in a 'fire and forget' mode, only trying to deliver each message once.
The delivery software on real mail servers, however, are proper SMTP implementations, and since the relevant RFCs state that you MUST retry delivery in case you encounter some classes of delivery errors, in almost all cases real mail servers will retry 'after a reasonable amount of time'.
Spammers do not retry. So if we set up our system to say essentially
"My admin told me not to talk to strangers"
- we should be getting rid of anything the sending end does not consider important enough to retry delivering.
The practical implementation is to record for each incoming delivery attempt at least
- sender's IP address
- the From: address
- the To: address
- time of first delivery attempt matching 1) through 3)
- time delivery of retry will be allowed
- time to live for the current entry
The first release of OpenBSD's spamd to support greylisting was OpenBSD 3.5. spamd's greylisting implementation operates only on individual IP addresses, and by default sets the minimum time before a delivery attempt passes to 25 minutes, the time to live for a greylist entry to 4 hours, while a whitelisted entry stays in the whitelist for 36 days after the delivery of the last message from that IP address. With a properly configured setup, machines that receive mail from your outgoing mail servers will automatically be whitelisted, too.
The great advantage to the greylisting approach is that mail sent from correctly configured mail servers will be let through. New correspondents will experience an initial delay for the first message to get through and their IP address is added to the whitelist. The initial delay will vary depending on a combination of the length of your minimum time before passing and the sender's retry interval. Regular correpondents will find that once they have cleared the initial delay, their IP addresses are kept in the whitelist as long as email contact is a regular affair.
And the technique is amazingly effective in removing spam. 80% to 95% or better reduction in the number of spam messages is frequently cited, but unfortunately only a few reports with actual numbers have been published. An often-cited report is Steve Williams' message on opensd-misc (available among other places at marc.info), where Steve describes how he helped a proprietary antispam device cope with an unexptected malware attack. He notes quite correctly that the blocked messages were handled without receiving the message body, so their apparently metered bandwidth use was reduced.
Even after more than four years, greylisting remains extremely effective. Implementing greylisting greatly reduces the load on your content filtering systems, but since messages sent by real mail servers will be let through, it will sooner or later also let a small number of unwanted messages through, and unfortunately it does not eliminate the need for content filtering altogether. Unfortunately you will still occasionally encounter some sites that do not play well with greylisting, see the references for tips on how to deal with those.
Do we need blacklists?
With greylisting taking care of most of the spam, is there still a place for blacklists? It's a fair question. The answer depends in a large part on how the blacklists you are considering are constructed and how much you trust the people who generate them and the methods they use.
The theory behind all good blacklists is that once an IP address has been confirmed as a source of spam, it is unlikely that there will be any valid mail send from that IP address in the foreseeable future.
With a bit of luck, by the time the spam sender gets around to trying to deliver spam to addresses in your domain, the spam sender will already be on the blacklist and will in turn treated to the s-l-o-w SMTP dialogue.
Knowing how a host makes it into a blacklist is important, but a clear policy for checking that the entries are valid and for removing entries is essential too. Once spam senders are detected, it is likely that their owners will do whatever it takes to stop the spam sending. Another reason to champion 'aggressive maintenance' of blacklists is that it is likely that IP addresses are from time to time reassigned, and some ISPs do in fact not guarantee that a certain physical machine will be assigned the same IP address the next time it comes online.
Your spamd.conf file contains a few suggested blacklists. You should consider carefully which ones to use. Take the time you need to look up the web pages listed in the list descriptions in the spamd.conf file and then decide which lists fit your needs. If you decide to use one or more blacklists, edit your spamd.conf to include those and set up a cron job to let spamd-setup load updated blacklists at regular intervals.
The lists I consider the more interesting ones are the nixspam list, with a 4 day expiry, and the uatraps list, with a 24-hour exiry. The nixspam list is maintained by ix.de, based on their logs of hosts that have verifiably sent spam to their mail servers. The uatraps list is worth looking into too, mainly because it is generated automatically by greytrapping.
Behavior based response: Greytrapping
Greytrapping is yet another useful technique that grew out of hands-on empirical study of spammer behavior, taken from the log data available at ordinary mail servers. You have probably seen spam messages offering lists of "millions of verified email addresses" available. However, verification goes only so far. You can get a reasonable idea of the quality of that verification if you take some time to actually browse mail server logs for failed deliveries to addresses in your domain. In most cases you will find a number of attempts at delivering to addresses that either have never existed or at least have no valid reason to receive mail.
The OpenBSD spamd developers saw this too. They also realized that what addresses are deliverable or not in your own domain is something you have complete control over, and they formulated the following rule to guide a new feature to be added to spamd:
"if we have one or more addresses that we are quite sure will never receive valid email, we can safely assume that any mail sent to those addresses is spam"that feature was dubbed greytrapping, and was introduced in spamd in time for the OpenBSD 3.7 release. The way it works is, if a machine that is already greylisted tries to deliver mail to one of the addresses on the list of known bad email addresses, that machine's IP address is added to a special local blacklist called spamd-greytrap. The address stays in the spamd-greytrap list for 24 hours, and any SMTP traffic from hosts in that blacklist is treated to the tarpit for the same period.
This is the way the uatraps list is generated. Bob Beck put a list of addresses he has referred to as 'ghosts of usenet postings past' on his local greytrap list, and started exporting the IP addresses he collects automatically to a freely available blacklist. As far as I know Bob has never published the list of email addresses in his spamtrap list, but the machines at University of Alberta appear to be targeted by enough spammers to count. At the time this article was written, the uatraps list typically contained roughly 120,000 addresses, and the highest number of addresses I have seen reported by my spamd-setup was just over 180,000 (it peaked later at just over 670,000 addresses). See Figure 1 for a graphical representation of the number of hosts in the uatraps list over the period February 2006 through early March 2008.

Figure 1: Hosts in uatraps
By using a well maintained blacklist such as the uatraps list you are likely to add a few more percentage points to the amount of spam stopped before it reaches your content filtering or your users, and you can enjoy the thought of actively wasting spammers' time.
A typical log excerpt for a blacklisted host trying to deliver spam looks like this:
Jan 16 19:55:50 skapet spamd[27153]: 82.174.96.131: connected (3/2), lists: uatraps Jan 16 19:59:33 skapet spamd[27153]: (BLACK) 82.174.96.131: <bryonRoe@boxerdelasgargolas.com> -> <schurkoxektk@ehtrib.org>
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: From: "bryon Roe" <bryonRoe@boxerdelasgargolas.com>
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: To: schurkoxektk@ehtrib.org
Jan 16 20:01:17 skapet spamd[27153]: 82.174.96.131: Subject: vresdiam
Jan 16 20:02:33 skapet spamd[27153]: 82.174.96.131: disconnected after 403 seconds. lists: uatraps
This particular spammer hung around at a rate of 1 byte per second for 403 seconds (six minutes, forty-three seconds), going through the full dialogue all the way up to the DATA part before my spamd rejected the message back to the spammer's queue.

Figure 2: Connection lengths measured at bsdly.net's spamd
That is a fairly typical connection length for a blacklisted host. Statistics from my sites (see Figure 2) show that most connections to spamd last from 0 to 3 seconds, a few hang on for about 10 seconds, and the next peak is at around 400 seconds. Then there's a very limited number that hang around for anywhere from 30 minutes to several hours, but those are too rare to be statistically significant (and damned near impossible to graph sensibly in relation to the rest of the data.
Interaction with a running spamd: spamdb
Your main interface to the contents of your spamd related data is the spamdb administration program. The command
$ doas spamdb
without any parameters will give you a complete listing of all entries in the database, whether WHITE, GREY or others. In addition, the program supports a number of different operations on entries in spamd's data, such as adding or deleting entries or changing their status in various ways. For example,
$ doas spamdb -a 192.168.110.12
will add the host 192.168.110.12 to your spamd's whitelist or update its status to WHITE if there was an entry for that address in the database already. Conversely, the command
$ doas spamdb -d 192.168.110.12
will delete the entry for that IP address from the database.
For greytrapping purposes, you can add or delete spamtrap email addresses by using a command such as
$ doas spamdb -T -a wkitp98zpu.fsf@datadok.no
to add that address to your list of spamtrap addresses. To remove the address, you substitute -d for the -a. The -t flag lets you add or delete entries for TRAPPED addresses manually.
Hitting back, poisoning their well: Summary of my field notes
Up util July 2007, I ran my spamd installations with greylisting, supplemented by hourly updates of the uatraps blacklist and a small local list of greytrapping addresses like the one in the previous section, which is obviously a descendant of a message-id, probably harvested from a news spool or from some unfortunate malware victim's mailbox. Then something happened that made me take a more active approach to my greytrapping.
My log summaries showed me an unusually high number of attempted deliveries to non-existent addresses in the domains I receive mail for. Looking a little closer at the actual logs showed spam backscatter: Somebody, somewhere had sent a large number of messages with made up addresses in one of our domains as the From: or Reply-to: addresses, and in those cases the to: address wasn't deliverable either, the bounce messages were sent back to our servers.
The fact that they were generating bounces to the spam messages indicates that any copies of those messages directed at actually deliverable addresses in those domains would have been delivered to actual users' mailboxes, not too admirable in itself.
Another variety that showed up when I browsed the spamd logs was this type:
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: Subject: Considered UNSOLICITED BULK EMAIL, apparently from you
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: From: "Content-filter at srv77.kit.kz" <postmaster@srv77.kit.kz>
Jul 13 14:36:50 delilah spamd[29851]: 212.154.213.228: To: <skulkedq58@datadok.no>
which could only mean that the administrators at that system had not yet learned that spammers no longer use their own From: addresses.
Roughly at that time it struck me:
- Spammers, one or more groups, are generating numerous fake and nondeliverable addresses in our domains.
- adding those generated addresses to our local list of spamtraps is mainly a matter of extracting them from our logs
- if we could make the spammers include those addresses in their To: addresses, too, it gets even easier to stop incoming spam and shift the spammers to the one-byte-at-a-time tarpit. Putting the trap addresses on a web page we link to from the affected domains' home pages will attract the address slurping robots sooner or later.
(Actually in the first discussions about this with my BLUG user group friends, we referred to this as 'brønnpissing' in Norwegian, which translates as 'urinating in their well'. The more detailed descriptions of the various steps in the process can be tracked via blog entries at http://bsdly.blogspot.com, starting with the entry dated Monday, July 9th, 2007, Hey, spammer! Here's a list for you!.)
Over the following weeks and months I collected addresses from my logs and put them on the web page at http://www.bsdly.net/~peter/traplist.shtml.
After a while, I determined that harvesting the newly generated soon-to-be-spamtrap addresses directly from our greylist data was more efficient and easier to script than searching the mail server logs. Using spamdb, you can extract the current contents of the greylist with
$ doas spamdb | grep GREY
which produces output in the format
GREY|96.225.75.144|Wireless_Broadband_Router|<aguhjwilgxj@bn.camcom.it>|<bsdly@bsdly.net>|1198745212|1198774012|1198774012|1|0
GREY|206.65.163.8|outbound4.bluetie.com|<>|<leonard159@datadok.no>|1198752854|1198781654|1198781654|3|0
GREY|217.26.49.144|mxin005.mail.hostpoint.ch|<>|<earle@datadok.no>|1198753791|1198782591|1198782591|2|0
where GREY is what you think it is, the IP address is the sending host's address, the third entry is what the sender identified as in the SMTP dialogue (HELO/EHLO), the fourth is the From: address, the fifth is the To: address. The next three are date values for first contact, when the status will change from GREY to WHITE and when the entry is set to expire, respectively. The final two fields are the number of times delivery has been blocked from that address and the number of conntections passed for the entry.
For our purpose, extracting the made up To: addresses in our domains from backscatter bounces, it is usually most efficient to search for the "<>" indicating bounces, then print the fifth field. Or, expressed in grep and awk:
$ doas spamdb | grep "<>" | awk -F\| '{print $5}' | tr -d '<>' | sort | uniq
will give you a sorted list of unique intended bounce-to addresses, in a format ready to be fed to a corresponding script for feeding to spamd. The data above and the command line here would produce
earle@datadok.no leonard159@datadok.no
- in some situations, the list will be a tad longer than in this ilustration. This does not cover the cases where the spammers apparently assume that any mail with From: addresses in the local domain will go through, even when they come from elsewhere. Extracting the fourth column instead
# spamdb | grep GREY | awk -F\| '{print $4}' | grep mydomain.tld | tr -d '<>' | sort | uniq
will give you a list of From: addresses in your own domain to weed out a few more bad ones from.
After a while, I started seeing very visible and measurable effects. At short intervals, we see spam runs targeting the addresses in the published list, working their way down in more or less alphabetical order. For example, in my field notes dated November 25, 2007, I noted
"earlier this month the address capitalgain02@gmail.com
started appearing frequently enough that it caught my
attention in my greylist dumps and log files. The earliest contact as far as I can see was at
Nov 10 14:30:57, trying to spam wkzp0jq0n6.fsf@datadok.no
from 193.252.22.241 (apparently a France Telecom customer).
The last attempt seems to have been ten days later, at
Nov 20 15:20:31, from the Swedish machine 217.10.96.36. My logs show me that during that period 6531 attempts
had been made to deliver mail from capitalgain02@gmail.com
via bsdly.net, from 35 different IP addresses, to 131 different
recipients in our domains. Those recipients included three
deliverable addresses, mine or aliases I receive mail for.
None of those attempts actually succeeded, of course."
It is also worth noting that even a decreipt the Pentium III 800MHz (since replaced with a Pentium 4 box, donations of more recent hardware gratefully accepted) at the end of the unexciting DSL line to my house has been able to handle about 190 simultaneous connections from TRAPPED addresses without breaking into a sweat. For some odd reason, the number of simultaneous connection a the other sites I manage with better bandwidth have not been as high as the ones from my home gateway.
During the months I've been running the trapping experiment, the number of spamtrap addresses in the published list has grown to more than 10,000 addresses (by May 4th, 2013, the list had grown to 24431 entries). Oddly enough, my greylist scans still show up a few more every few days.
Meanwhile, my users report that spam in their mailboxes is essentially non-existent. On the other side of the fence, there are indications that it may have dawned on some of the spammers that generating random addresses in other people's domains might end up poisoning their own well, so they started introducing patterns to be able to weed out their own made up addresses from their lists. I take that as a confirmation that our harvesting and republishing efforts have been working rather well.
The method they use is to put some recognizable pattern into the addresses they generate. One such pattern is to take the victim domain name, prepend "dw" and append "m" to make up the local part and then append the domain, so starting from sia.com we get dwsiam@sia.com.
There is one other common variation on that theme, where the prepend string is "lin" and the append string is "met", producing addresses like linhrimet@hri.de. Then again when they use that new, very recognizable, address to try to spam my spamtrap address malseeinvmk@bsdly.net, another set of recognition mechanisms are activated, and the sending machine is quietly added to my spamd-greytrap. (We've since seen other patterns come and go, scanning the list at http://www.bsdly.net/~peter/traplist.shtml will see examples of them all).
And finally, there are clear indications that spammers use slightly defective relay checkers that tend to conclude that a properly configured spamd is an open relay, swelling my greylists temporarily. We already know that the spammers do not use From: addresses they actually receive mail for, and consequently they will never know that those messages were in fact never delivered.
If you've read this far and you're still having fun, you can find other anecdotes I would have had a hard time believing myself a short time back in my field notes at bsdly.blogspot.com. By the time the magazine has been printed and distributed (or by the time you find this revised article online), there might even be another few tall tales there.
You might also want to read
The Book of PF, 4th Edition, by Peter N. M. Hansteen, No Starch Press 2026 (covers both pre-4.7 and post-4.7 syntax), available in better bookshops or from the publisher
The Next Step in the Spam Control War: Greylisting, by Evan Harris. Available at http://greylisting.org/articles/whitepaper.shtml
Maintaining A Publicly Available Blacklist - Mechanisms And Principles, April 14, 2013 describes the maintenance regime for the published version of my spamd-greytrap list
In The Name Of Sane Email: Setting Up OpenBSD's spamd(8) With Secondary MXes In Play - A Full Recipe, May 28, 2012, offers another, more OpenBSD-centric, recipe for setting up a spamd based system.
This article originally appeared in BSD Magazine #2, June 2008. This re-publication has suffered only minor updates and edits.
If you're interested in OpenBSD in general, you have a real treat coming up in the form of Michael W. Lucas' Absolute OpenBSD, 2nd edition. If a firewall or other networking is closer to your heart, you could give my own The Book of PF and the PF tutorial (or here) it grew out of. You can even support the OpenBSD project by buying the books from them at the same time you buy your CD set, see the OpenBSD Orders page for more information.
Upcoming talks: I'll be speaking at BSDCan 2013, on The Hail Mary Cloud And The Lessons Learned, with a preview planned for the BLUG meeting a couple of weeks before the conference. There will be no PF tutorial at this year's BSDCan, fortunately my staple tutorial item was crowded out by new initiatives from some truly excellent people.
Subscribe to:
Posts (Atom)





{kind=link}
{kind=link}